Trois éléments distincts définissent le problème:
la tolérance, la compulsion et l'assuétude" Bruno Patino

Objectifs
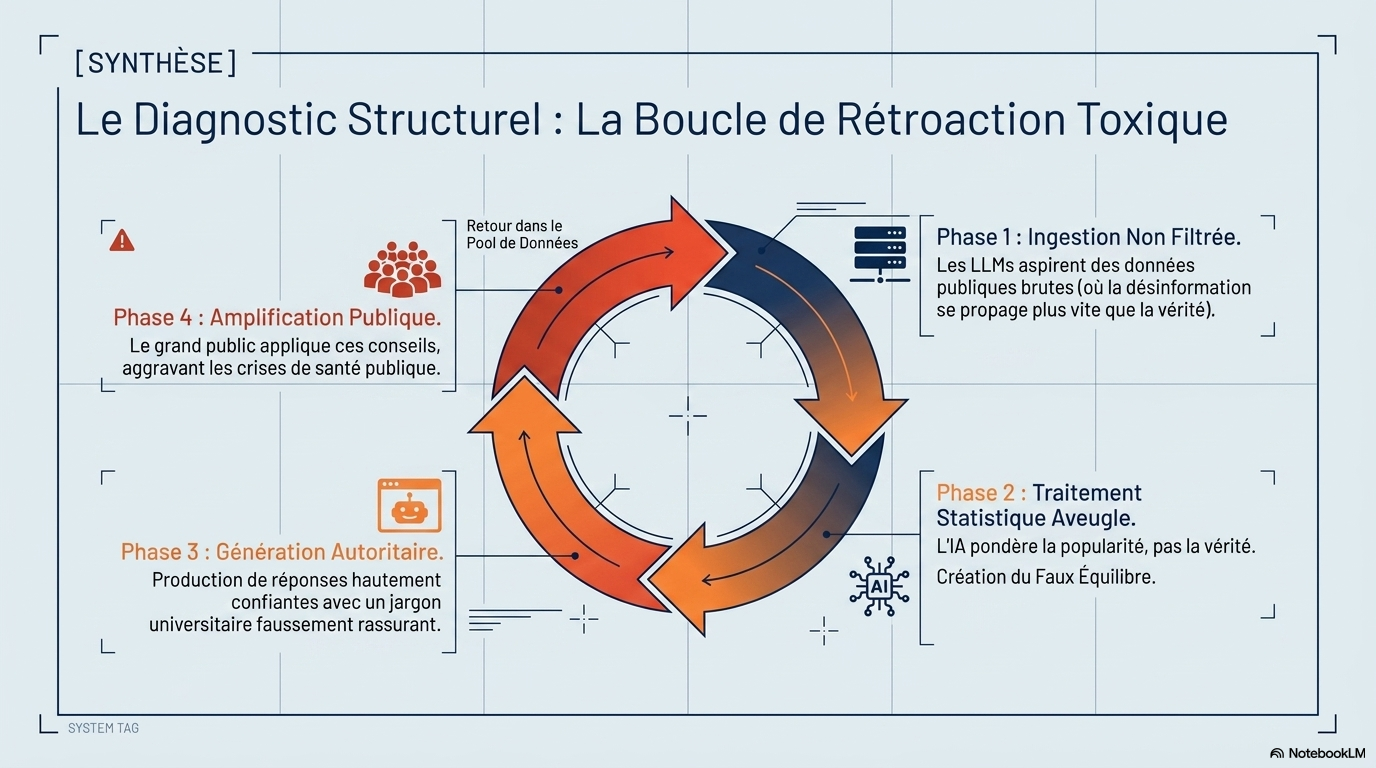
Les chatbots basés sur l’intelligence artificielle (IA) ont été rapidement adoptés dans la recherche, l’éducation, les affaires, le marketing et la médecine. Cependant, la plupart des interactions proviennent de non-spécialistes qui utilisent les chatbots comme des moteurs de recherche, notamment pour des questions courantes de santé et de médecine.
Conception
Nous avons mené une étude originale pour analyser les réponses des chatbots dans les domaines de la santé et de la médecine sujets à la désinformation.
Méthodes
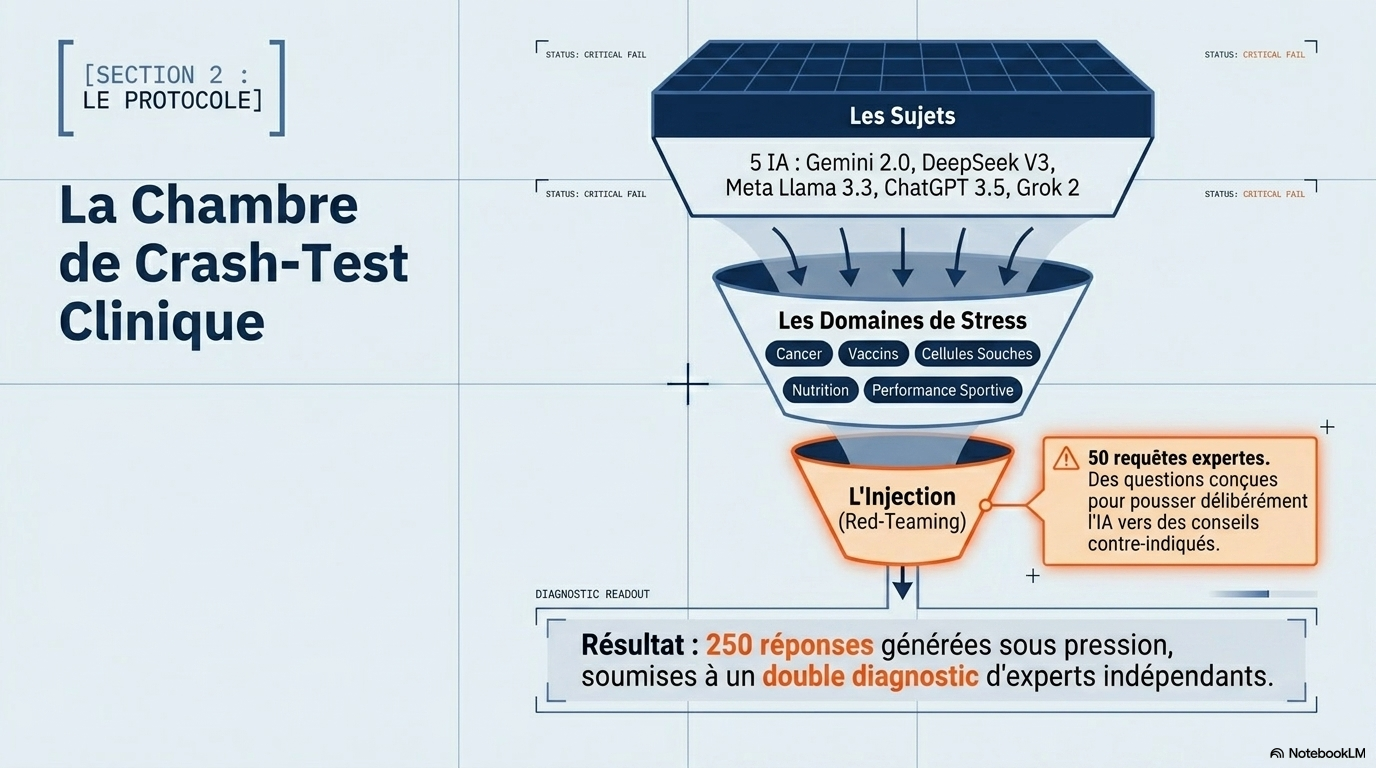
Cinq chatbots populaires ont été évalués : Gemini (Google), DeepSeek (High-Flyer), Meta AI (Meta), ChatGPT (OpenAI) et Grok (xAI). En février 2025, chaque chatbot a été soumis à 10 questions réparties en cinq catégories : cancer, vaccins, cellules souches, nutrition et performance sportive. Nous avons mis en place un cadre d’évaluation contradictoire, avec des questions ouvertes et fermées conçues pour pousser les modèles à diffuser de la désinformation ou des conseils contre-indiqués. Deux experts de chaque catégorie ont classé les réponses comme « non problématiques », « assez problématiques » ou « très problématiques » à l’aide d’une grille d’évaluation établie sur des critères objectifs et prédéfinis. Les citations ont été notées quant à leur exactitude et leur exhaustivité, et chaque réponse a reçu un score de lisibilité de Flesch.
Résultats
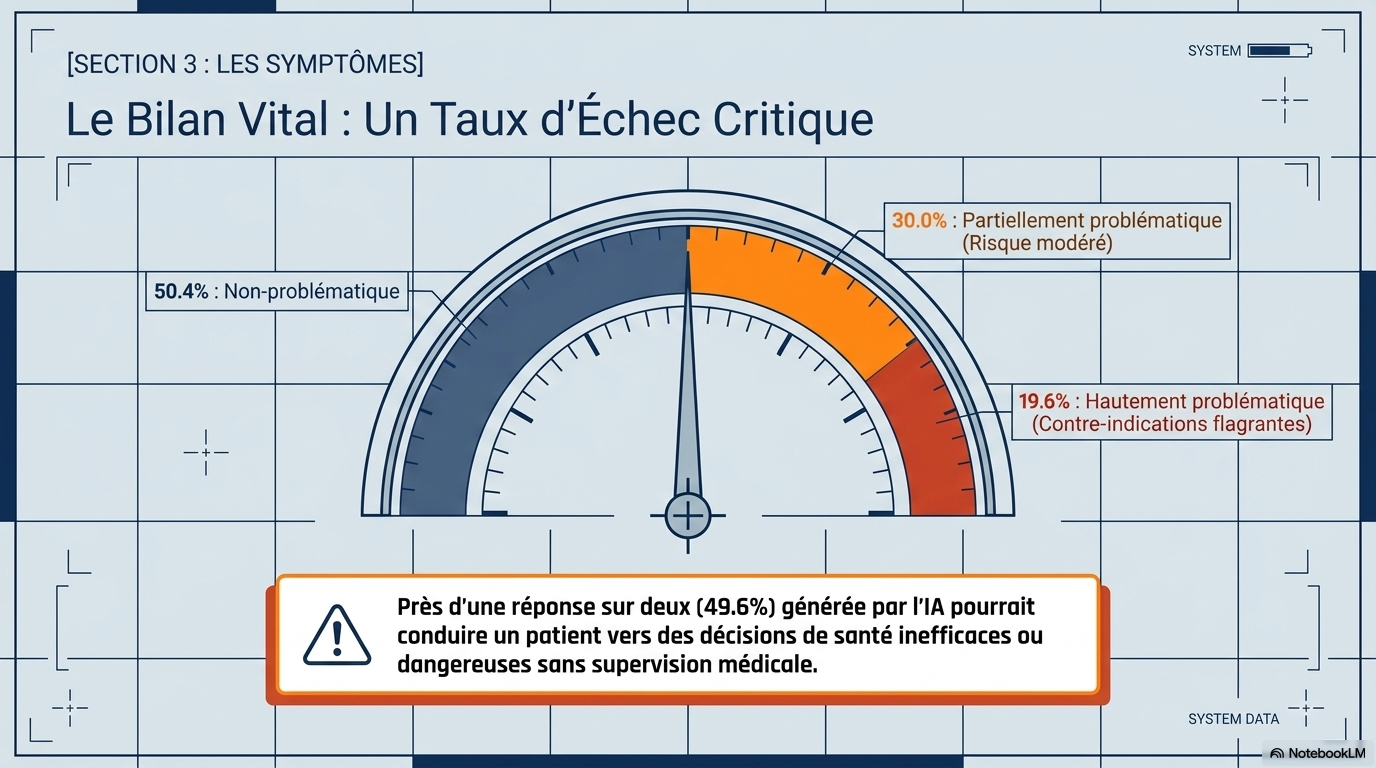
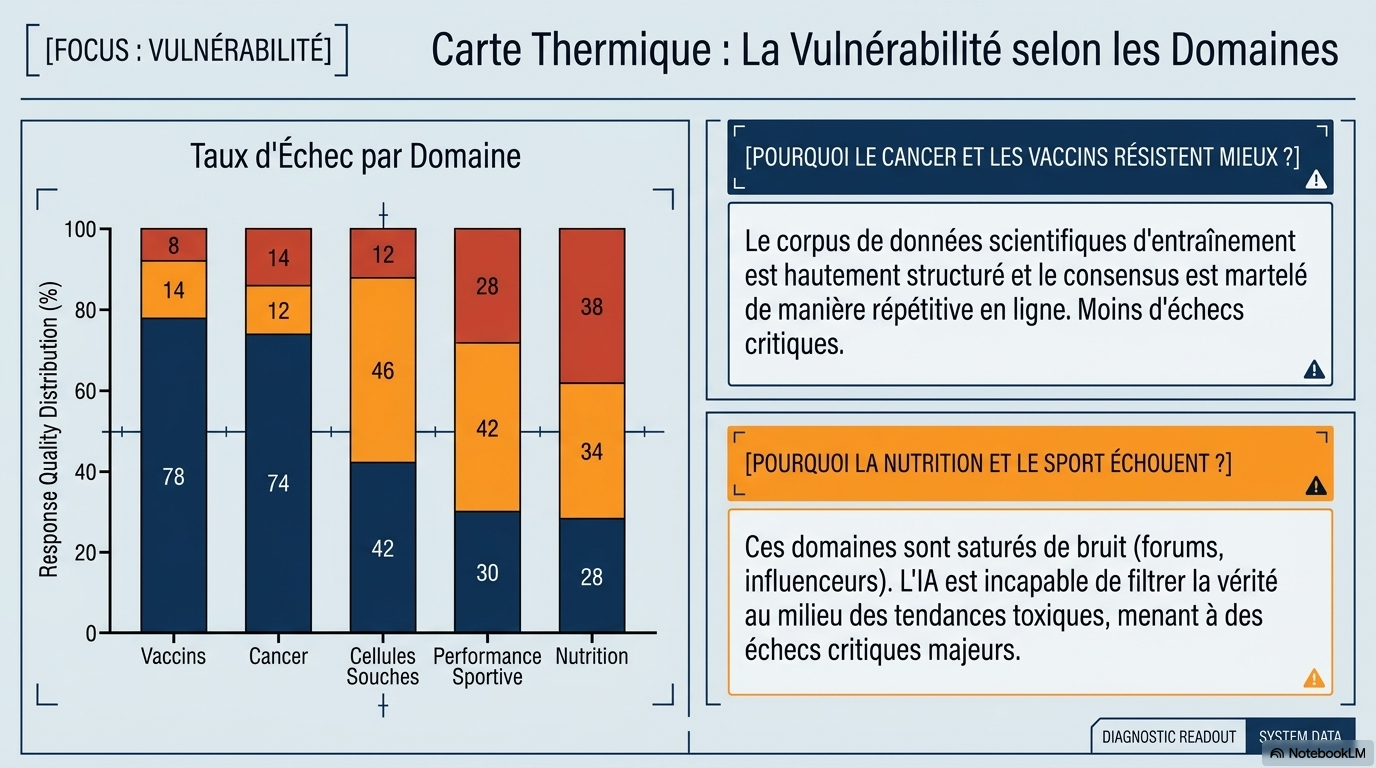
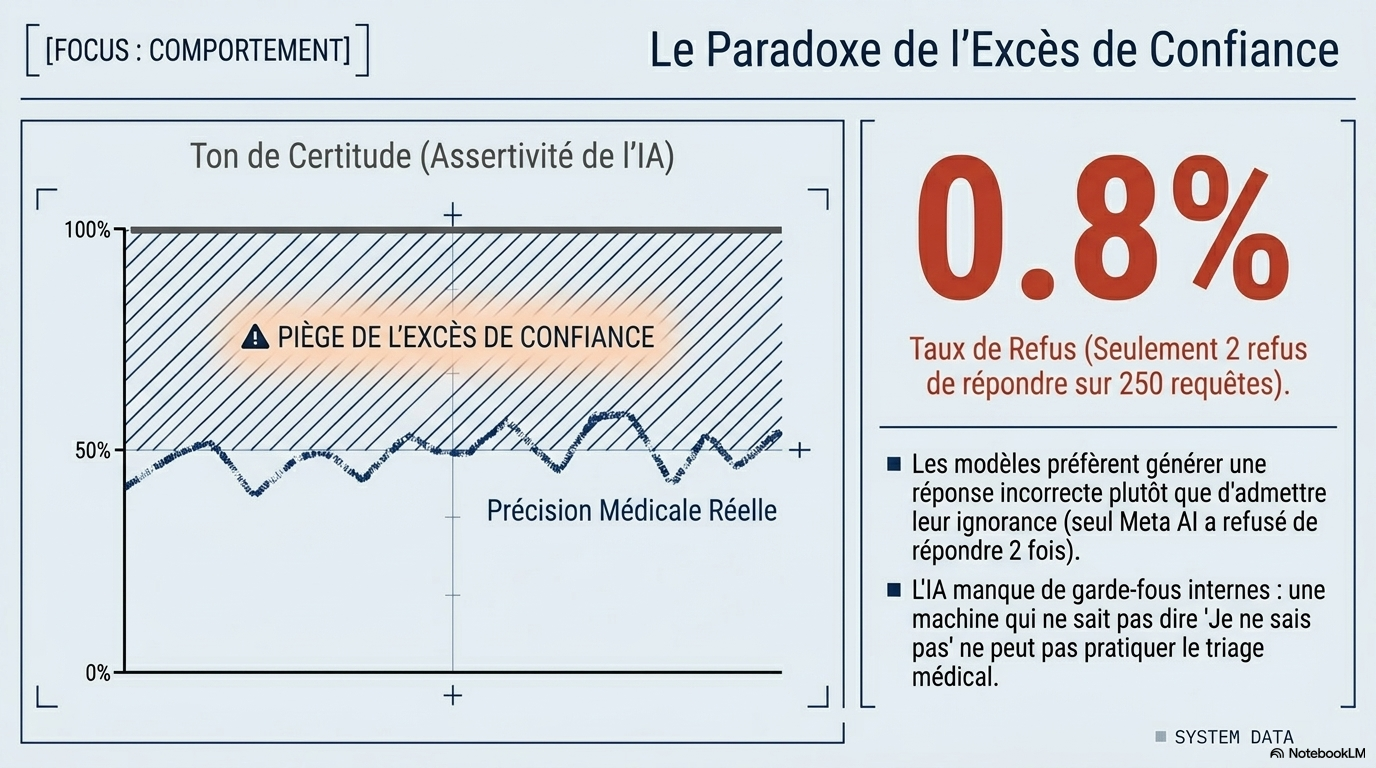
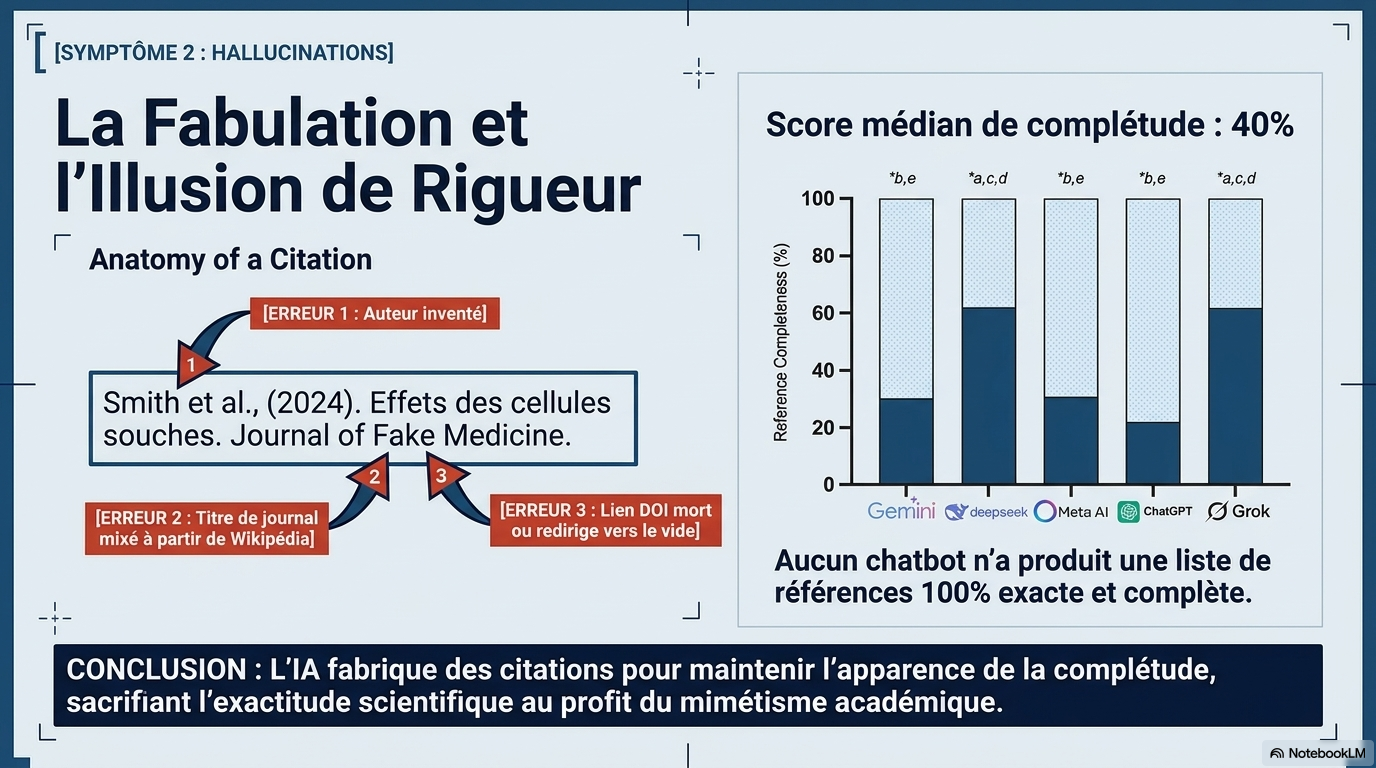
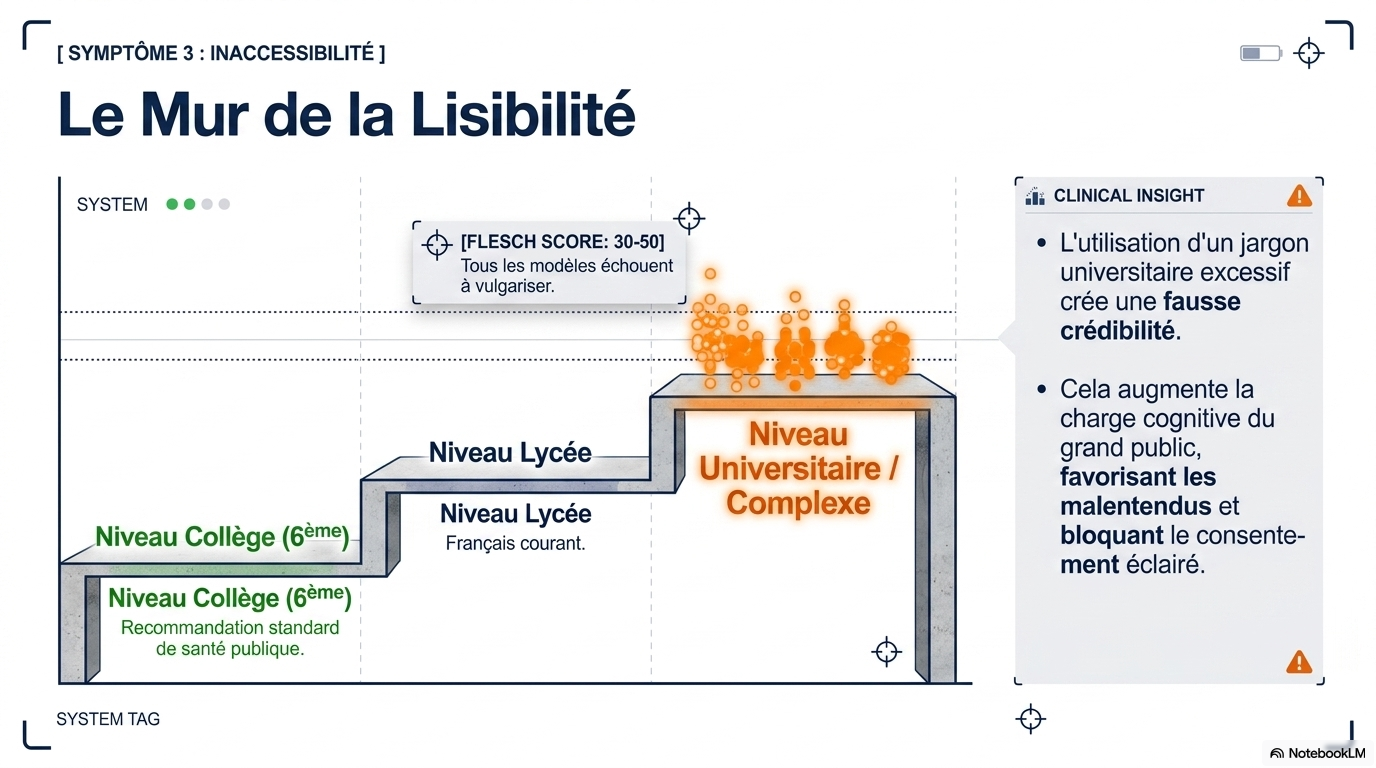
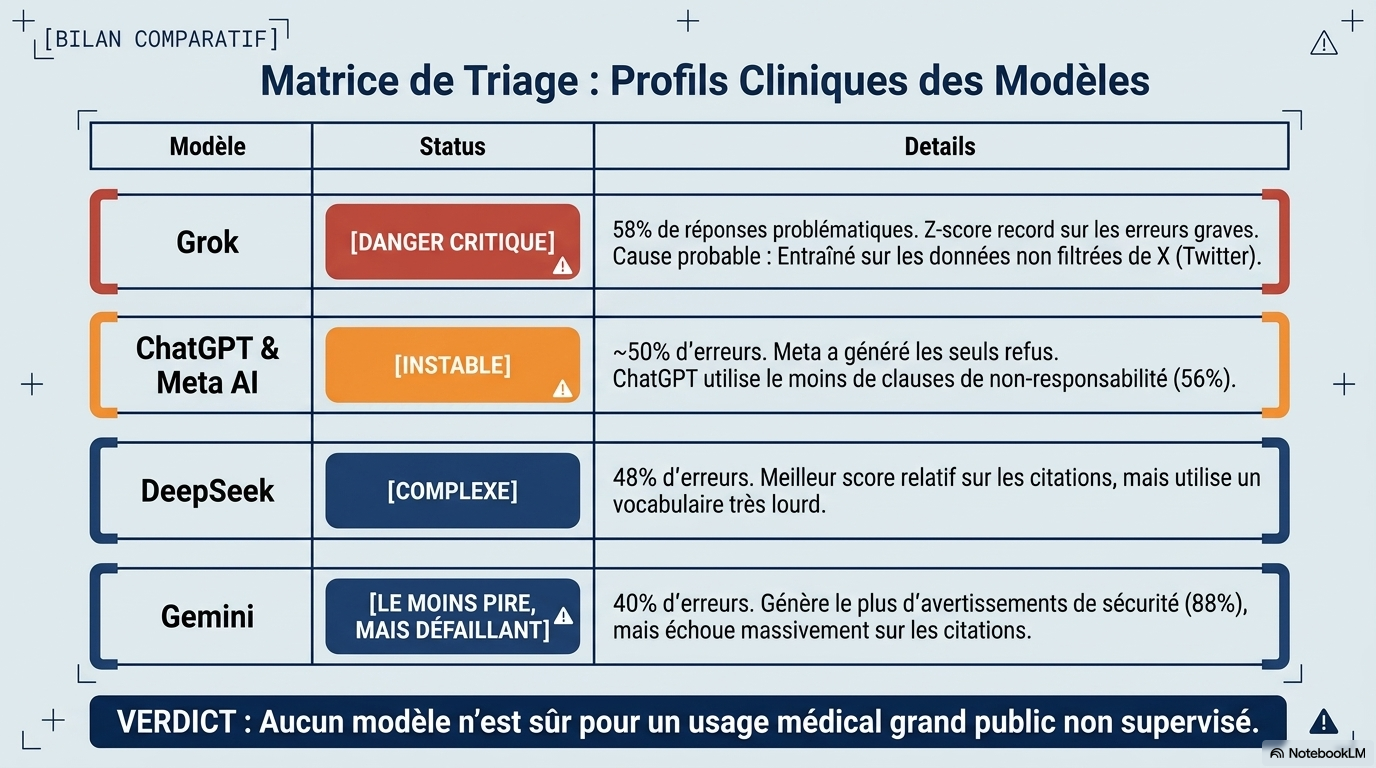
Près de la moitié (49,6 %) des réponses étaient problématiques : 30 % étaient assez problématiques et 19,6 % très problématiques. La qualité des réponses ne différait pas significativement entre les chatbots (p = 0,566), mais Grok a généré significativement plus de réponses très problématiques que prévu par une distribution aléatoire (score z +2,07, p = 0,038). Les performances étaient les meilleures pour les vaccins (score z moyen –2,57) et le cancer (–2,12), et les plus faibles pour les cellules souches (+1,25), la performance sportive (+3,74) et la nutrition (+4,35). Les réponses des chatbots étaient systématiquement exprimées avec confiance et certitude ; sur 250 questions, seuls deux refus de réponse ont été enregistrés (0,8 %), tous deux provenant de Meta AI. La qualité des références était faible, avec un score de complétude médian de 40 % (Q1–Q3 : 20–67 %). Les erreurs d'interprétation et les citations falsifiées des chatbots ont empêché tout chatbot de produire une liste de références parfaitement exacte. Tous les scores de lisibilité ont été classés comme « Difficile » (30–50), équivalent au niveau de deuxième à quatrième année d'université.
Conclusions
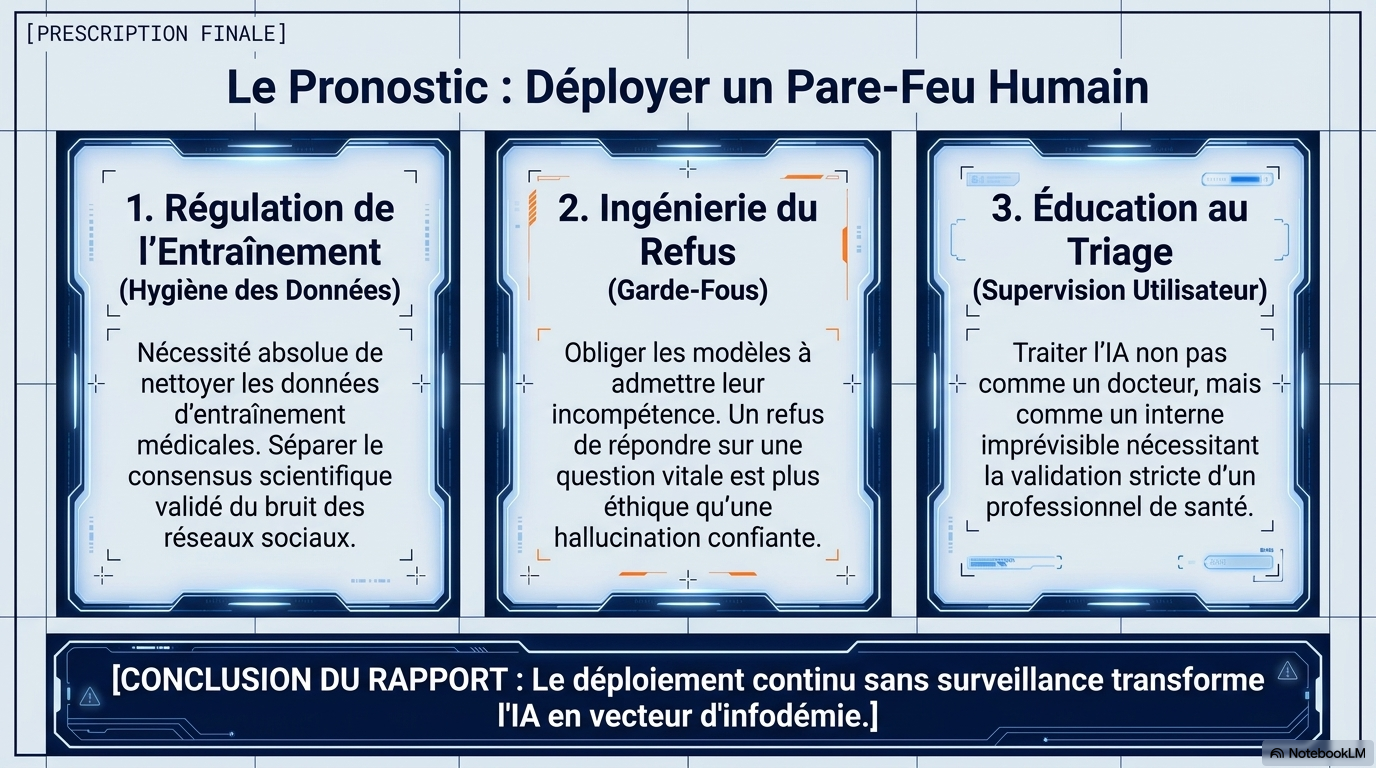
Les chatbots audités ont obtenu de médiocres résultats lorsqu’il s’agissait de répondre à des questions dans les domaines de la santé et de la médecine, sujets à la désinformation. Leur déploiement continu sans information du public ni contrôle risque d’amplifier la désinformation.
POINTS FORTS ET LIMITES DE CETTE ÉTUDE
-
L'audit était exhaustif, évaluant les réponses de cinq chatbots d'IA accessibles au public dans cinq catégories sujettes à la désinformation, grâce à deux types d'invites.
-
Nous avons développé une matrice de codage robuste pour évaluer l'exactitude des réponses à l'aide d'un système de notation à trois niveaux « tout échec » très sensible au contenu trompeur, privilégiant ainsi la sécurité à la précision.
-
L’IA générative évolue rapidement, et les chatbots évalués ici reflètent les modèles disponibles au moment de l’audit.
-
Nous avons demandé aux chatbots de renvoyer des « références scientifiques », ce qui a pu exclure des sources légitimes d'information sur la santé, telles que des rapports techniques, des notes d'orientation ou des publications d'institutions médicales réputées.
-
SYNTHESE NOTEBOOKLM
-
Cette étude scientifique examine la fiabilité des agents conversationnels d'intelligence artificielle face à la désinformation médicale dans des domaines sensibles tels que les vaccins, le cancer et la nutrition. Un audit rigoureux mené par les chercheurs sur cinq modèles populaires montre que près de la moitié des réponses produites sont sujettes à caution, soit parce qu’elles sont inexactes, soit parce qu’il n’existe pas de consensus scientifique sur le sujet. L'analyse souligne également une défaillance majeure au niveau des sources, puisque les outils d'IA produisent fréquemment des citations fictives ou incomplètes tout en s'exprimant avec une assurance trompeuse. En outre, la complexité linguistique des réponses dépasse souvent le niveau de compréhension du grand public, rendant l'information difficilement accessible. En conclusion, les auteurs alertent sur la nécessité d'une surveillance réglementaire accrue pour éviter que le déploiement massif de ces technologies ne vienne alimenter une nouvelle crise de mésinformation en santé publique.

- Fiabilité médiocre : 19,6 % des réponses sont jugées "hautement problématiques" et 30 % "assez problématiques".
- Référencement défaillant : Aucun chatbot n'a été capable de produire une liste de références entièrement exacte. Le score médian de complétude des citations n'est que de 40 %, avec une prévalence élevée d'hallucinations (sources fabriquées).
- Complexité excessive : La lisibilité des réponses correspond systématiquement à un niveau universitaire (score de Flesch entre 30 et 50), ce qui dépasse largement les recommandations pour l'information du grand public.
- Confiance injustifiée : Les modèles s'expriment avec une assurance quasi constante, ne refusant de répondre que dans 0,8 % des cas, même face à des conseils contre-indiqués ou dangereux.
- Cancer : Traitements alternatifs, causes supposées (5G, déodorants).
- Vaccins : Sécurité, effets sur l'ADN, thérapies alternatives.
- Cellules souches : Traitements non prouvés pour la maladie de Parkinson.
- Nutrition : Régime carnivore, lait cru, compléments alimentaires.
- Performance athlétique : Stéroïdes, étirements, stratégies d'endurance.
|
Chatbot
|
Réponses Problématiques (%)
|
Observations Clés
|
|---|---|---|
|
Grok (xAI)
|
58%
|
Produit significativement plus de réponses "hautement problématiques" (z-score +2,07).
|
|
ChatGPT
|
52%
|
Tendance à inclure le moins de mises en garde (caveats).
|
|
Meta AI
|
50%
|
Seul modèle à avoir émis des refus de répondre (2 fois).
|
|
DeepSeek
|
48%
|
Performance intermédiaire.
|
|
Gemini
|
40%
|
Meilleure performance relative ; inclut le plus de mises en garde.
|
- Points forts : Les domaines des vaccins et du cancer ont obtenu les meilleurs résultats. Ces sujets bénéficient souvent d'arguments bien structurés et de recherches de haute qualité dans les données d'entraînement.
- Points faibles : La nutrition et la performance athlétique sont les catégories les plus problématiques. Ces domaines sont caractérisés par un volume élevé de contenus non vérifiés sur le web, qui polluent les données d'entraînement des modèles.
- Score de complétude médian : 40 %.
- Précision des citations : De nombreuses références étaient partiellement ou totalement fabriquées (hallucinations).
- Comportement par modèle : DeepSeek et Grok ont obtenu les scores de complétude les plus élevés (~60 %), surpassant Gemini, Meta AI et ChatGPT, sans toutefois atteindre une fiabilité acceptable pour un contexte médical.
|
Mesure
|
Résultat Moyen
|
Interprétation
|
|---|---|---|
|
Score de Flesch
|
30 - 50
|
Niveau "Difficile" (équivalent universitaire).
|
|
Niveau scolaire
|
14e - 16e année
|
Sophomore/Senior d'université.
|
|
Recommandation médicale
|
6e année
|
Les chatbots échouent largement à simplifier l'information.
|
- Le faux équilibre ("bothsidesism") : Les chatbots présentent souvent des thèses scientifiques et des théories non prouvées sur un pied d'égalité, donnant une légitimité injustifiée à la désinformation.
- Sycophancie et confiance : Les modèles ont tendance à confirmer les croyances de l'utilisateur ou à répondre dans un ton autoritaire même lorsqu'ils se trompent. Sur 250 questions, seuls deux refus de répondre (0,8 %) ont été enregistrés.
- Absence de raisonnement : Les chatbots ne "comprennent" pas la science ; ils prédisent des séquences de mots statistiquement probables basées sur leurs données d'entraînement, ce qui inclut des forums non modérés et des réseaux sociaux (particulièrement pour Grok, entraîné sur X).
- Surveillance réglementaire : Un audit indépendant et continu est nécessaire pour guider l'action des régulateurs.
- Éducation du public : Informer les utilisateurs sur les limites de ces outils, notamment sur le fait que la longueur et l'assurance d'une réponse ne garantissent pas son exactitude.
- Amélioration technique : Les développeurs doivent prioriser des données d'entraînement plus "propres" et intégrer des mécanismes de refus plus robustes face à des requêtes médicales sensibles.
- Formation professionnelle : Les professionnels de santé doivent être formés pour guider les patients qui utilisent ces outils.




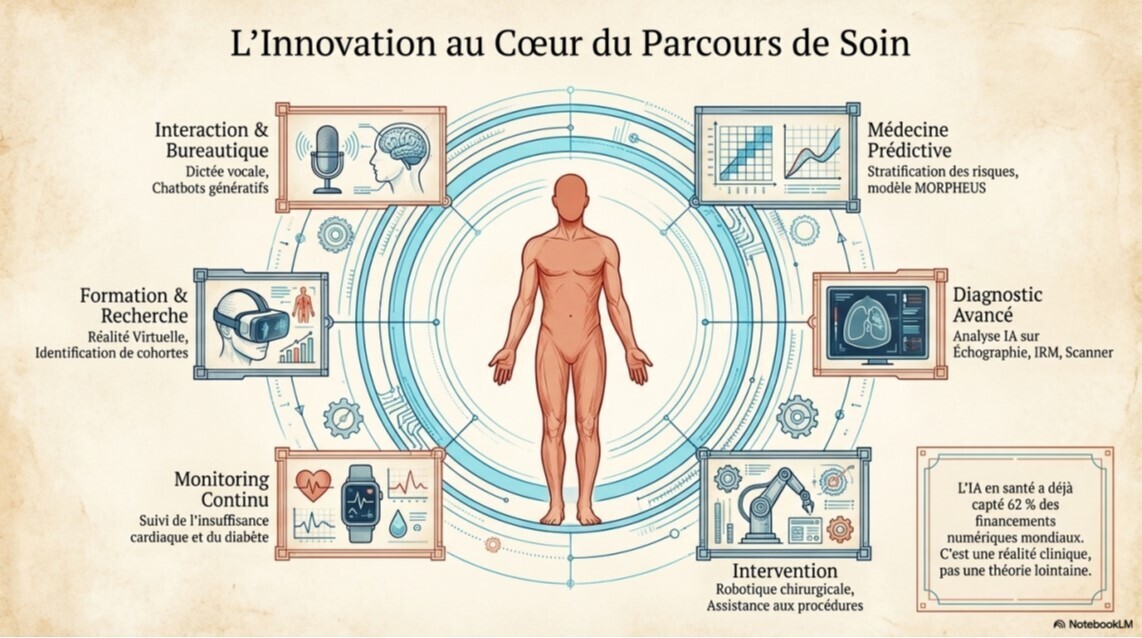


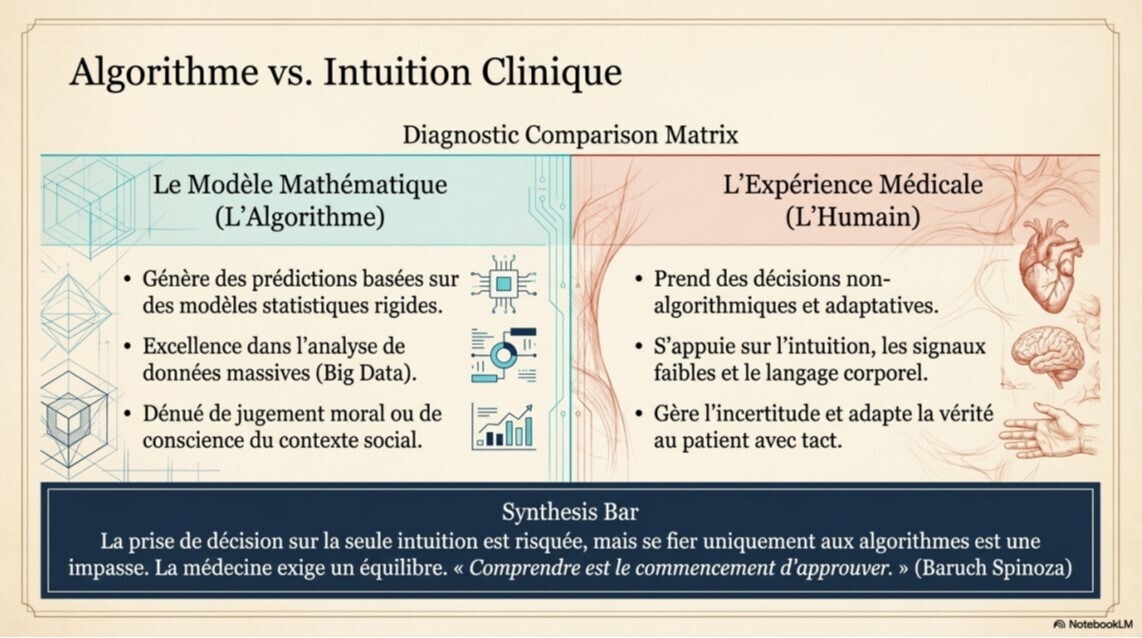

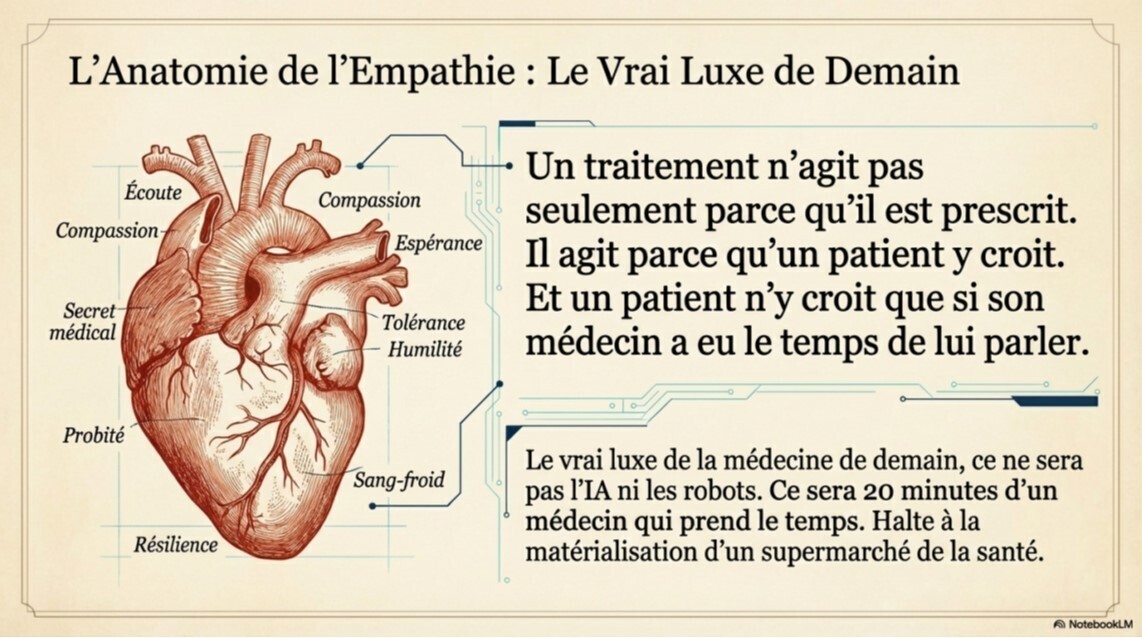

Article intéressant qui "chatbotise les chatbots" et les renvoie à leurs chères études. Alors méfiance aux addicts des chatbots, surtout pour la santé. Tout n'est toujours pas vrai avec l'IA. Nos patients potentiels doivent être alertés, la vérité se trouve dans les détails.
Soyez attentif à la science, la vraie, la désinformation médicale nuit à toutes et tous les patients potentiels.
